Conduit
Conduit is a plugin based framework that functions like a data pipeline. Conduit is primarily intended to allow dApp developers to customize the data the dApp wants to monitor/aggregate/act on from the Algorand Blockchain.
Conduit can be used to:
- Build a notification system for on chain events.
- Power a next generation block explorer.
- Select dApp specific data and act on specific dApp transactions.
- Identify and act on dApp specific Token actions/movements.
- Identify and act on specific Algorand transactions based on Address or other transaction properties.
- Build a custom Indexer for a new ARC.
- Send blockchain data to another streaming data platform for additional processing (e.g. RabbitMQ, Kafka, ZeroMQ).
- Build an NFT catalog based on different standards.
- Have Searchability on a massively reduced set of transactions, requiring much less disk space.
Note
Full documentation for the Conduit framework is available in the Conduit Github repository.
Installing Conduit¶
Conduit can be installed by downloading the built binaries, using a docker image on docker hub, or built from source. Full instructions for Installation of Conduit are described in the Conduit Github Repository.
Conduit Architecture¶
The framework consists of three primary plugin components, Importers, Processors, and Exporters. Importer plugins are designed to source data into the pipeline, Processors manipulate or filter the data, and Exporter plugins act on the processed data. Within a given instance of Conduit, the pipeline supports one importer and one exporter, while zero or more processor plugins can be used.
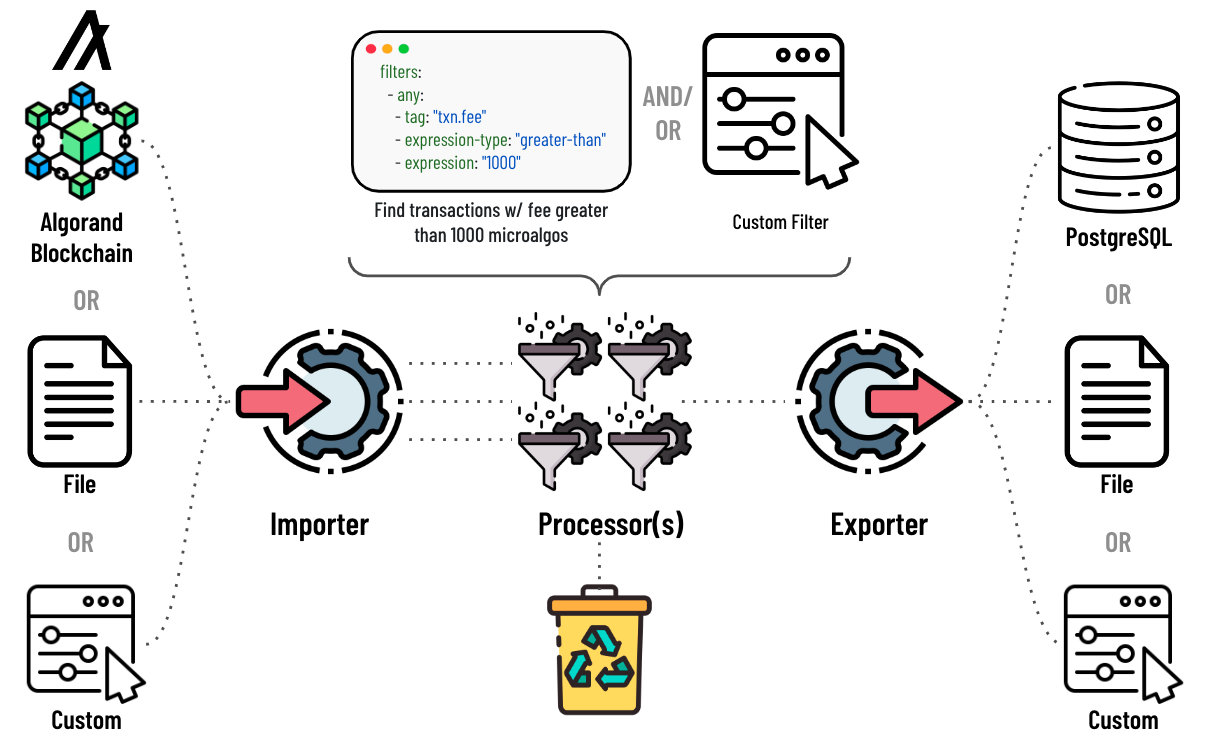
Default installations of the conduit binaries include two types of importers (algod and file_reader). The algod plugin is used to source data from an Algorand Follower node or an Archival node. Using a Follower node is the recommended approach as you have access to more data for use in the processor and also have access to the postgresql exporter. The file_reader plugin can be used to source block data from the filesystem. Most dApps will most likely use the algod importer.
The default installation provides one processor that filters the data based on transaction properties. This plugin (filter_processor) will be described in more detail in a subsequent section.
The default installation provides two exporters (postgresql and file_writer). The file_writer exporter, writes block data to the filesystem. The postgresql exporter writes block data to a postgreSQL database.
Configuring Conduit¶
Conduit is configured by defining all the plugins the pipeline will support in a YAML file called conduit.yml. These plugins must be built and part of the binaries that the specific instance of Conduit is using. This file is used to define which importer, processors, and exporter plugin a particular instance is using. In addition, individual plugin properties are also configured in the YAML file as well. For more information on creating and configuring the YAML file see the Conduit documentation.
Note
Multiple instances of Conduit can be running simultaneously, with different configurations. No two instances can use the same follower node though.
Running Conduit¶
Once Installed and configured, start Conduit with your data directory as an argument:
./conduit -d data
Warning
This data directory should be unique to conduit. This is not the data directory that algod uses.
Customizing Conduit¶
In addition to the default plugins described above, the Conduit framework allows custom plugins to be developed allowing dApp developers total customization of how the data is sourced, processed and stored or acted on. This process is described in detail with several tutorials available in the Conduit Github repository. The Conduit team also hosts a known list of externally developed plugins.
Note
The Conduit team is actively looking for sample plugins that illustrate interesting use cases. If you build a plugin and want to share your work, please file a PR on the Conduit repository to add it to that page.
Using the Indexer API with an Instance of Conduit¶
When using Conduit, some dApps may wish to continue to use the Indexer API that Algorand provides. If your application will require this API, you will need to setup the Conduit pipeline as described in the Conduit documentation.
Note
The 2.X versions of Indexer used all the blockchain data since its inception. With Conduit, you can decide how much data you really want to store and search with the Indexer API.
Filtering Block Data¶
One of the primary use cases of Conduit is to filter data that a specific dApp is interested in examining or acting on. To accommodate this, the default installation of Conduit provides the filter_processor. This filter is configured similarly to the following in config.yml.
name: filter_processor
config:
# Whether the expression searches inner transactions for matches.
search-inner: true
# Whether to include the entire transaction group when the filter
# conditions are met.
omit-group-transactions: true
# The list of filter expressions to use when matching transactions.
filters:
- any:
- tag: "txn.rcv"
expression-type: "equal"
expression: "ADDRESS"
After specifying the proper name and two basic parameters, one or more filters can be added to the YAML file to specify particular transactions your dApp is interested in. In the above example, Conduit will only store/act on transactions where a specific address is the receiver of a transaction. Developers can set any number of filters, specifying different tags, expression-types and expressions. The tag property has access to all transaction properties defined in the Developer documentation. In addition, if your instance of Conduit is attached to a Follower node, the filter can also tag specific data in the ApplyData set. ApplyData contains data that needs to be applied to the ledger, based on the results of a transaction(s). This includes properties like changes to Closing Amount , Application State, etc. The full list of available properties in the ApplyData set is available in the Conduit Documentation. For more information and examples of other filters see the Conduit filter examples.